That’s not normal…
Through an average day the volume of queries seen at each of our nameservers shows a reasonable level of variation. In most cases what we see is a regular daily pattern with a certain degree of noise and the odd spike here and there.
However; sometime after 13:00 on the 8 February it was noticed that the traffic to one of our nodes (LCY1) had jumped up massively:
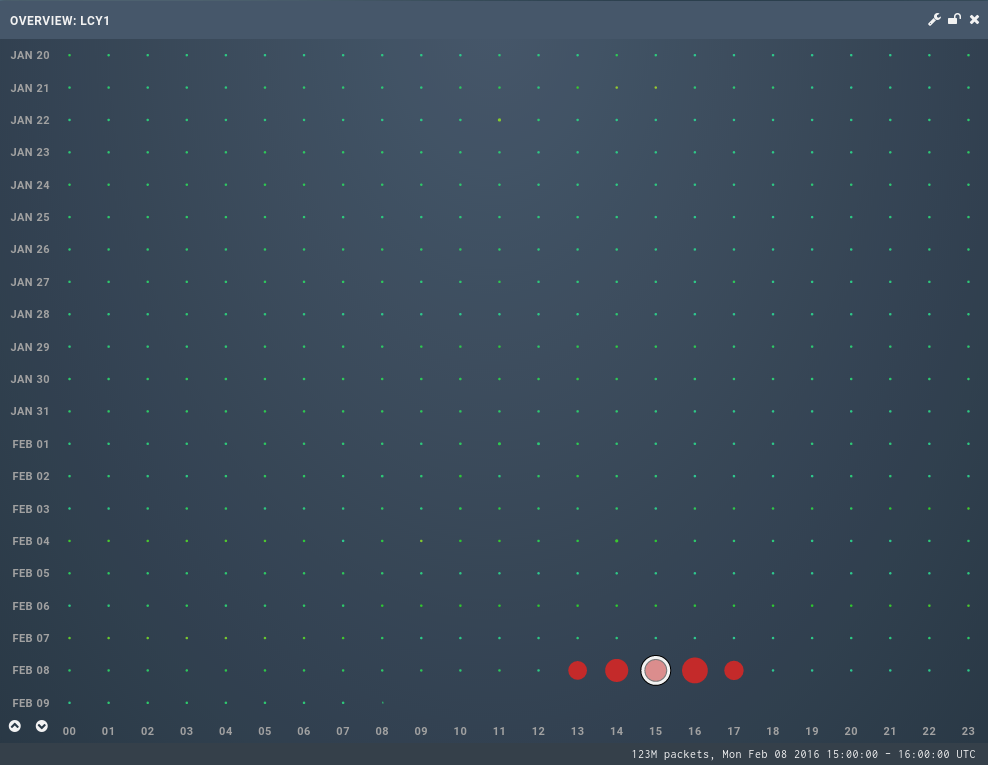
In the space of a few minutes the traffic went from around 4,000 queries per second (qps) to nearly 35,000 qps (123M queries per hour); the increase coming from a badly formed DNS with QTYPE0:

to which we were responding “FORMERR”:

What was happening?
All of this extra traffic was (apparently) coming from a single IP address but this being UDP (which can easily be spoofed) we initially investigated the possibility of a DoS attack.
However, as DoS attacks using DNS go, this would be a very strange one for a number of reasons:
- FORMERR is not a good way of getting amplification of your traffic
- in fact our responses are smaller than the queries in this case so there is a reduction
- The traffic was only hitting a single node
- why only use one mirror when many more are available?
- The IP TTLs were all identical
- so it looks like a single source which makes spoofing less likely
Also the nature of the queries was odd… All from port 22772, all garbage (from a DNS point of view) and tellingly all containing the same payload “RRQ must be sent first”. This particular message can be generated by a TFTP server (where a session is initiated by a read request, or RRQ) in response to an unexpected incoming packet.
Fortunately, using turing, we can see the exact sequence of packets sent from a particular IP address. Of particular interest is the last genuine query sent from that IP address:
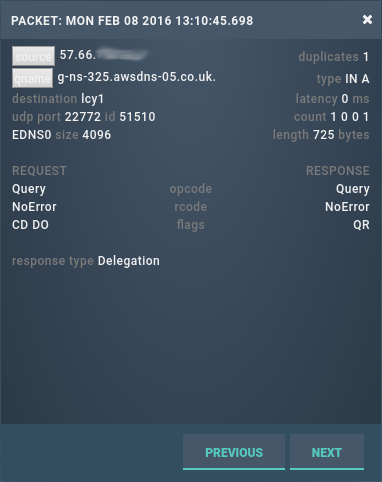
As we can see, this is a well-formed request from port 22772 which we replied to with a delegation. 0.025 seconds later we received the first of the barrage of badly formatted requests:
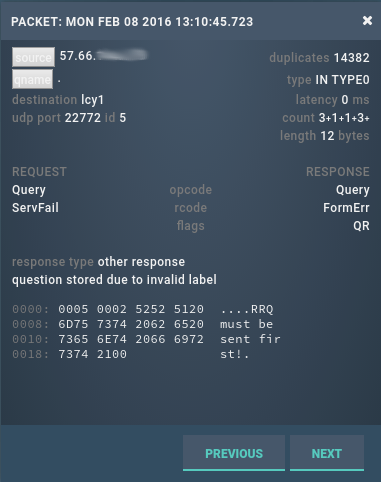
So our response generated a response from them, which we (try to) interpret as a query and when we can’t, we send the response “FORMERR”; a response to which they respond “RRQ must be sent first”… and the loop continues ad infinitum (like machines playing pong).
Their response suggested that the machine has at least a DNS client (possibly a recursive server) and TFTP running on it. The DNS client is correctly using source port randomisation, but if it happens to pick the port in use by TFTP then that service intercepts the response.
What was done?
The IP address does occasionally send genuine queries – a few hundred to a few thousand had been seen each day the previous week – so we did not want to cut it off completely. However initial attempts to create rules to drop just the bad traffic proved difficult as our load balancer saw all the traffic as a single flow. Therefore, as a last resort, the IP address was given a null route on the LCY1 router (i.e. all outgoing traffic would be dropped). What happened was a near instantaneous fall in the traffic from the source IP, as you can see below:

This nails the cause as “machine pong”; as soon as the cycle was broken the traffic stopped (note that the null route still allowed incoming traffic). The null route was subsequently lifted and (so far) we have not seen this traffic return. Of course if they are still running their server then each genuine query runs a chance of setting off the chain once more.
One outstanding question for us is why didn’t response rate limiting (RRL) kick in? The nameserver involved was apparently configured to do this limiting, and each error response should have contributed to it being triggered. The nature of this event means that even dropping a single response would be enough to stop it in its tracks. Sure enough, it was determined that RRL was not correctly configured at that time. We now have it running and occasionally we see short bursts of this behaviour; but they do not have the chance to develop to the scale seen here before the RRL kicks in.
This event shows the usefulness of being able to drill into traffic in real time to see what exactly is happening and why. Turing allowed us to quickly find the anomalous traffic that could potentially have affected services for days or weeks.