…a little ugly on the side.
Spam, junk or unsolicited email is a permanent component of internet traffic. It increases and decreases in volume but it is always there.
By virtue of our role in answering questions directing machines to the part of the internet covered by the namespace “.uk”; we see a good proportion of queries being made by systems delivering email. In DNS terms we see requests for the mail exchange (MX) record of a domain. If, for example, I send an email to “[email protected]” my email system will need to know where to deliver that message to, and so will request the MX record for nominet.uk. So, if we see an increase in MX requests at our servers the most likely explanation is an increase in emails being sent to addresses which end “.uk”.
When sending unsolicited emails there is a higher than usual chance that the recipient domain doesn’t exist, and so our response will be “non-existant domain” (NXDOMAIN). The reasons for this are many fold; but old stale lists are often used, or people who know the existence of a .com domain strip the .com off, add “.co.uk” or “.uk” instead and send an email to “[email protected]” hoping for a hit both on the domain and the recipient. The economics of sending large amounts of email are such that this method is seen as viable in some quarters; although we have seen a significant reduction in this sort of behaviour over the last five years or so (see cutwail blog article).
So, when we started to see MX requests peaking and a corresponding increase in NXDOMAIN responses it started to bring back memories. It’s always nice to dig a bit deeper into this sort of traffic just in case there is something interesting in it. Here we see two views of just such an event; one where we look at 4 weeks worth of traffic filtered to just MX queries:
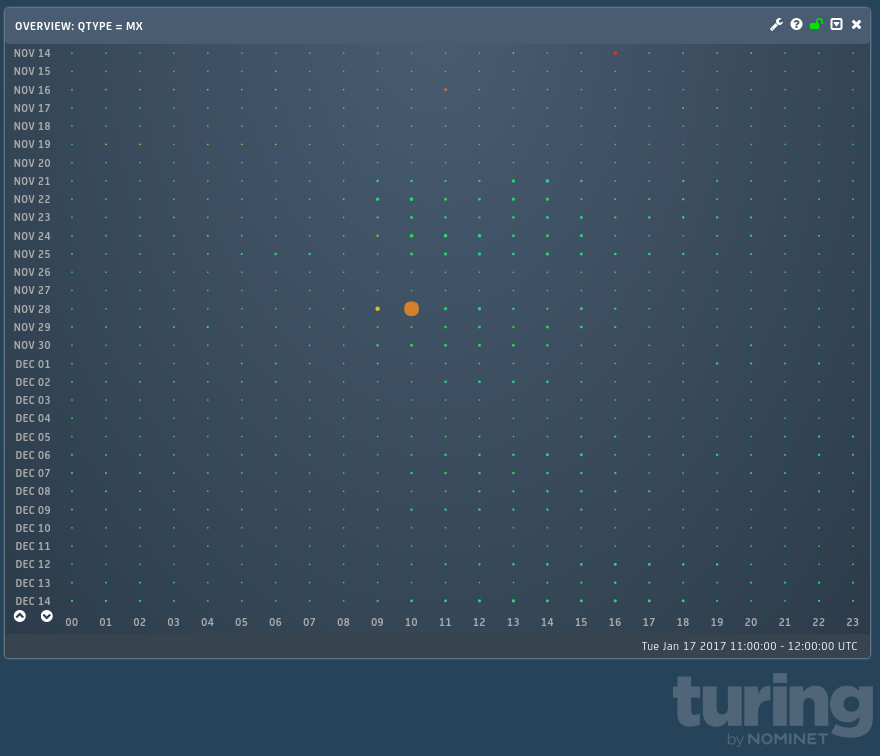
This shows us just how anomalous the event we are looking at is. We can also look at the general traffic seen around the same time:

which shows us the scale and duration of the event. So we can see that for around an hour our single largest request type is MX records; both the scale and sudden onset of this traffic tell us that it is not human driven and there is little doubt that this traffic is generated by a botnet.
Another angle to look at is to take some of the NXDOMAIN requests and see if we can work out why they have been made, has the TLD been switched or is something else happening? Let’s look at the traffic at the lowest level that we can, the individual packets.
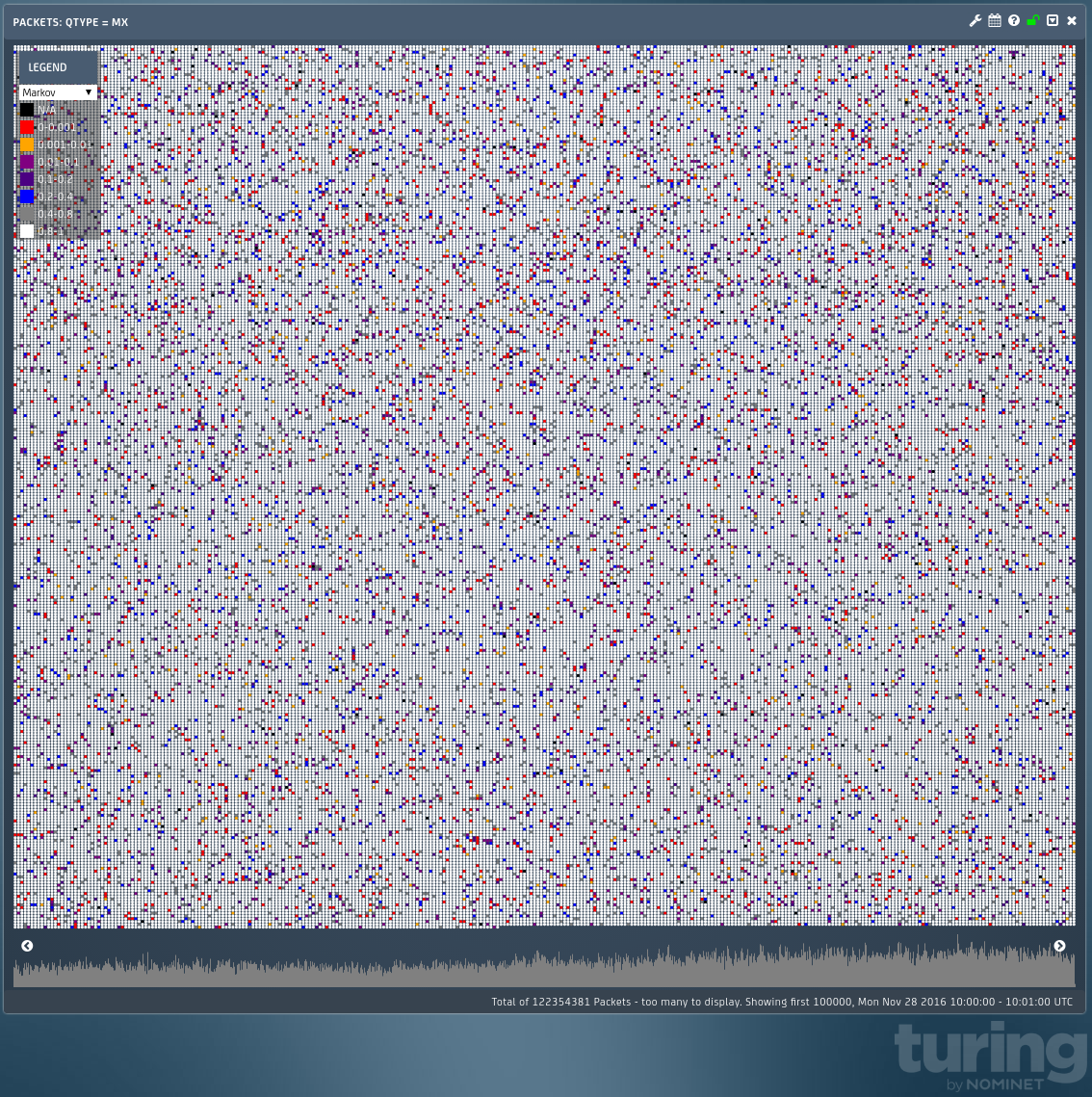
In this view we have coloured by the relative transition probability of the domain name being looked up. In short this gives us a score between 0 and 1 which tells us the similarity between this name and some other large set of strings, or dictionary. (In our case we have taken every domain name ever registered under .uk; and so the score tells us how similar to a genuine registration the name is.) To get to the really odd looking, automatically generated even, domain names we just look at the very low scores as an example we see:
ehhxqjtpoxs.co.uk
This name is sufficiently random looking that finding it in another top level domain (TLD) would be an extreme coincidence; and sure enough there is no obvious record of it. What you might come across however is another blast from the (recent) past, a page which identifies itself as a “spambot killer”. The idea is simple enough, one way in which spam lists are populated is via spiders that crawl the web looking for something that looks like an email address. These get added to a list and once on they get passed around, sold and reused. If you can pollute these lists by, say, publishing large amounts of non existent email addresses, you can skew the economics of sending spam and make it less profitable. The problem is that while the first part works, in that you can get the spambot to add your rubbish addresses to its list, the second part doesn’t. Sending spam is so cheap that hit rates (in terms of valid addresses) have to get extremely low before it becomes unprofitable.
Okay, so we have this random string which we can see published on a spambot killer page, but is that just coincidence? Well possibly, but then what if we see a second domain from that page (e.g. o5017zxpo9.co.uk) being queried? Or a third (e.g. qxj44e2bv1w.co.uk)? Are you ready to buy a lottery ticket yet? These pages also have domains made up from the concatenation of plausible words; so we also see requests for (non-existent) domains like commercebusinesstraining.co.uk and sure enough we see them in our data also.
What is actually being sent to those email addresses that happen to exist? We assume that this is a pretty low-rent spam service and therefore expect emails which reflect that fact; but there really is only one way to find out… collect some. So we registered some of the random, non-existent domains and delegated them to our own servers. We then directed email requests to a server which would accept mail for any user, a spamtrap if you like.
What we see is a steady stream of emails using one of a variety of hooks designed to make the recipient open the attached file. These usually play on natural curiosity or anxieties about fraud; as an example one email claimed that the attached file is a purchase order. Is it misdirected? Has someone somehow cloned my credit card and used it to make a purchase? Has one of my online accounts been compromised?
To increase authenticity the email comes complete with a signature disclaimer that matches the apparent from address; all from a genuine company that will be completely innocent and have nothing to do with this email at all. (It is relatively simple to make an email appear to have come from a particular sender without having any relationship to that sender at all.)
So, what happens if we open the attachment? Well we don’t know exactly, but nothing good… A short while after getting the email we uploaded the attachment to virustotal where 12/55 antivirus engines tested against identified the file as a trojan downloader, some giving the family as “nemucod”. This piece of software has one job when running on a machine, and that is to download and install code, most likely malware of some sort. But look at that detection score, a few hours later it has risen to 19/55 but that still means that many machines with up-to-date antivirus running would still happily allow the user to open the file.
I have to admit, given the provenance of this email I was slightly surprised that the payload could fool so many antivirus engines. I assumed that the low-rent end of spam campaigns would result in low-end malware delivery, maybe what this shows is that economics makes even low-end malware tricky to detect and stop.